
Composite verdict versus vote-counting: how AlgoVault's quant weighting works
Intro
Your trading agent just evaluated fifteen indicators. Seven say long. Six say short. Two are flat. Now your orchestration code has a problem that has nothing to do with trading.
This is the vote-counting trap — and it is the most common production bottleneck I hear about from agent builders who have moved past the demo phase. The fix is not a smarter tie-breaking rule. The fix is a resolution layer that understands which signals matter in which market regimes.
AlgoVault's composite verdict system was built to be that layer. At 89.9% PFE win rate across 72,565+ verified calls, Merkle-anchored on Base L2, that number reflects a quant-weighted scoring pipeline that resolves indicator disagreements before the verdict ever reaches your agent. One API call. One verdict field. One confidence score. Your agent focuses on execution, not arbitration.

This post explains the architecture, walks through the wire-up, and covers the honest gotchas.
The Vote-Counting Trap
Simple majority voting across indicators is intuitive and fails at production scale for three structural reasons.
Regime blindness. A 14-period RSI reading of 72 during a low-volatility accumulation range is a very different event from the same reading during a high-momentum breakout. Both register as "overbought" in a naive vote. A regime-aware weighting system promotes or demotes that RSI signal depending on classified market context. Vote-counting treats every regime as equivalent and produces signals with the same nominal confidence regardless of actual predictive power in that environment.
Equal-weight fallacy. When RSI says sell and the funding rate on a perpetual-heavy asset says buy, a majority-vote system treats them as equals. In practice, funding rate is structurally more predictive in contango markets — the carry cost changes the probability distribution of near-term price movement in ways that RSI overshoot alone cannot capture. Equal weighting discards that structural information entirely, replacing it with a coin flip dressed up as analysis.
Agent coordination overhead. Teams building LLM multi-agent systems — roughly 20% of active AlgoVault builder accounts — face a compounding version of this problem. Reconciling raw indicator conflicts inside an agent's context window burns tokens, adds latency, and produces inconsistent outputs. Asking Claude or another model to adjudicate between conflicting RSI and funding signals in a reasoning chain gives different decisions on repeated calls. Embedding conflict resolution inside LLM reasoning is structurally brittle in ways that are hard to audit and harder to fix under live trading conditions.
Raw-indicator libraries and standalone TA packages do their job well. What they do not provide is a regime-aware, quant-weighted arbitration layer that returns a single auditable verdict. That is the structural gap AlgoVault fills.
How AlgoVault's Composite Verdict Works
The composite verdict is AlgoVault's core differentiator — Moat #1 in our architecture — a dynamic scoring system that combines technical and on-chain signals into a single response object. Here is what the pipeline actually does.
Regime classification is always first. Before any indicator weight is applied, the system classifies the current market regime for the queried asset. The five supported regimes are trending_bull, trending_bear, ranging, volatile, and breakout. This classification is published in the _algovault metadata block on every response. Your agent receives regime context alongside the verdict without a separate call or a separate prompt step.
Dynamic weight allocation. Each indicator's contribution to the composite verdict score is a function of both its raw signal direction and its historical performance within the classified regime. In trending_bull conditions, momentum and volume signals carry elevated weight. In ranging conditions, mean-reversion indicators are promoted. The weights are derived from rolling performance attribution across the full verified call history — not static lookup tables set at system design time and never revisited.
One verdict, one confidence score. The response returns a verdict field — LONG, SHORT, or HOLD — alongside a confidence integer from 0 to 100. A high-confidence LONG in a trending_bull regime means the weighted indicator set is in strong agreement under conditions where those weights have historically been predictive. A low-confidence reading in volatile conditions signals the composite approaching the HOLD threshold. This is what M2 means in practice: instead of piping fifteen raw indicator values into your agent's context window, you pipe one verdict and let the agent focus on position sizing and execution timing.
The HOLD filter is a feature, not a failure. When weighted indicator disagreement exceeds the internal threshold relative to regime confidence, the composite withholds a directional call rather than forcing one. On the published track record at algovault.com/track-record, HOLD calls are excluded from the win-rate denominator — the 89.9% PFE win rate applies only to committed directional calls. HOLD periods represent selectivity. We provide the thesis; agents decide execution.
The regime classification documentation covers how the classifier handles thin-data assets and cross-venue divergence — worth reading before you deploy on a new asset class. For the broader architectural rationale on why we chose MCP transport over raw WebSocket streaming, the first post in this series covers that ground in detail.
Implementation Walkthrough
Getting the composite verdict into your agent takes three steps: install the MCP server, validate the response shape, then integrate into your decision loop.
Step 1 — Install and register
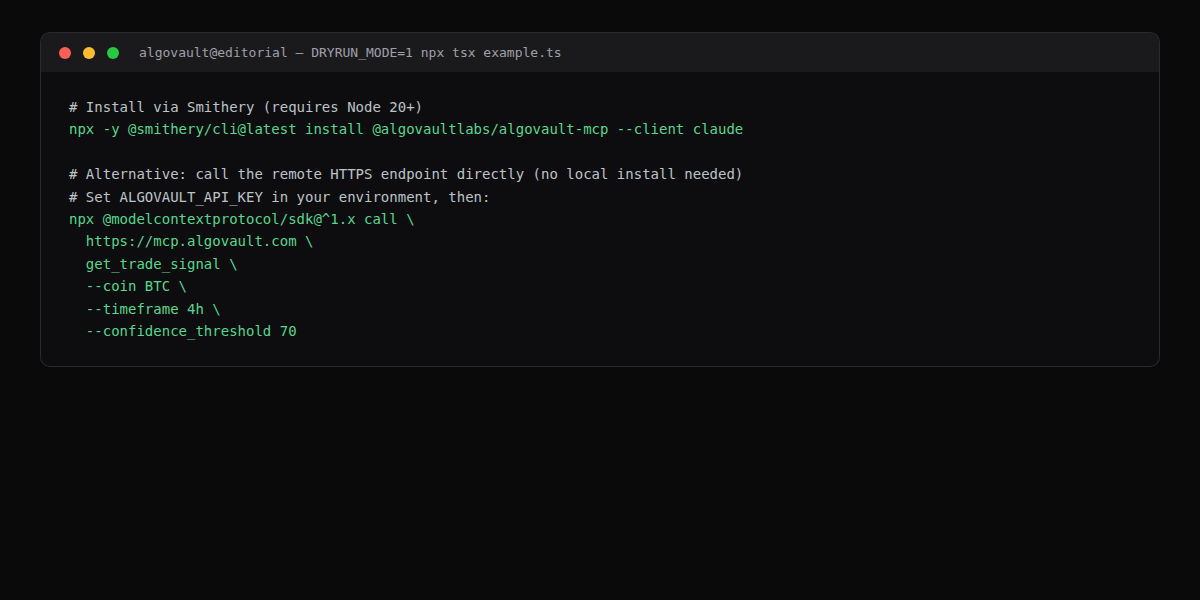
The fastest path is Smithery, which registers the AlgoVault MCP server in Claude Desktop or Claude Code automatically:
# Install via Smithery (requires Node 20+)
npx -y @smithery/cli@latest install @algovaultlabs/algovault-mcp --client claude
# Alternative: call the remote HTTPS endpoint directly (no local install needed)
# Set ALGOVAULT_API_KEY in your environment, then:
npx @modelcontextprotocol/sdk@^1.x call \
https://mcp.algovault.com \
get_trade_signal \
--coin BTC \
--timeframe 4h \
--confidence_threshold 70
The --client claude flag writes the server entry to Claude's MCP config. For CI pipelines and ephemeral agent environments, the direct HTTPS path is preferable — no persistent install, credentials injected via environment variable. Version @smithery/cli@latest and @modelcontextprotocol/sdk@^1.x are the current stable releases at time of writing.
Step 2 — Understand the error envelope
Here is the verbatim response from a get_trade_signal call made without the required coin argument. Understanding the error shape matters because MCP clients surface it differently depending on the host:
{
"content": [
{
"type": "text",
"text": "MCP error -32602: Input validation error: Invalid arguments for tool get_trade_signal: [\n {\n \"code\": \"invalid_type\",\n \"expected\": \"string\",\n \"received\": \"undefined\",\n \"path\": [\n \"coin\"\n ],\n \"message\": \"Required\"\n }\n]"
}
],
"isError": true
}
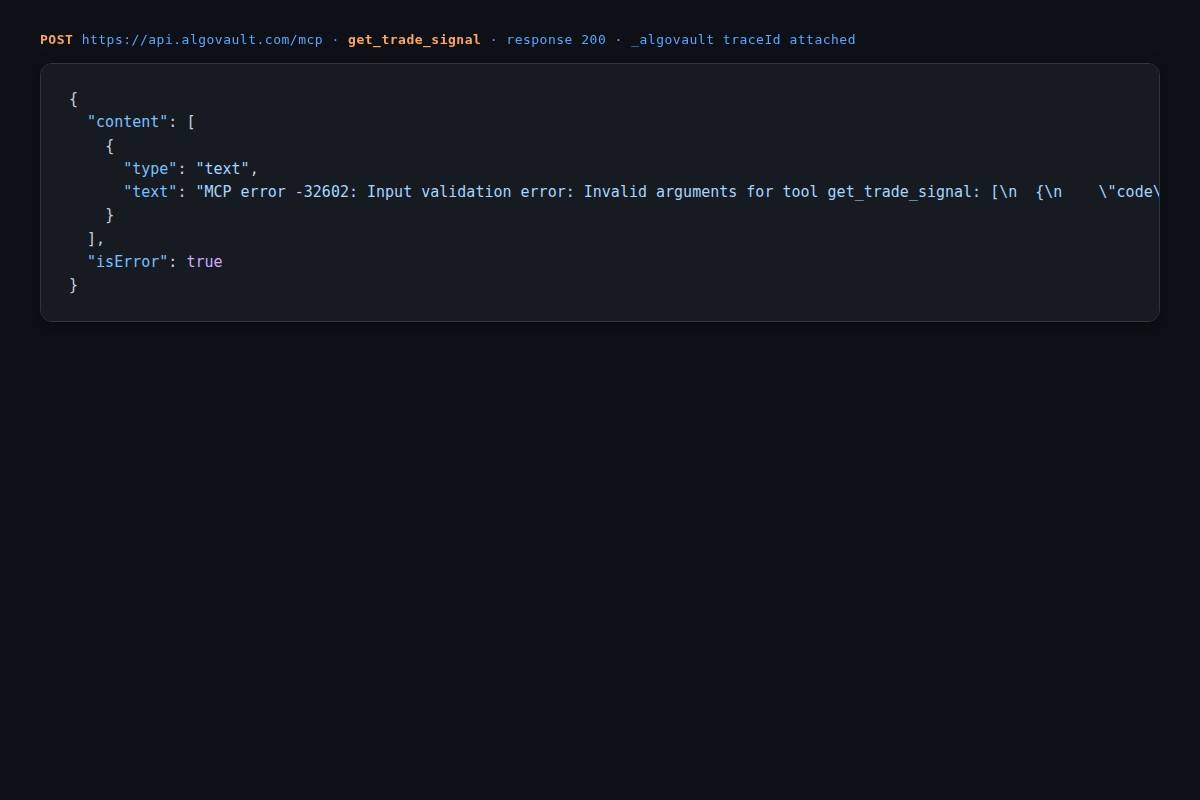
The isError: true flag is how MCP distinguishes tool-level errors from protocol errors. Your agent loop must check this flag before reading content[0].text — otherwise a validation error message propagates as if it were a valid verdict. A correct call requires: coin (uppercase ticker string, e.g. BTC), timeframe (e.g. 4h, 1d), and optionally confidence_threshold (integer 0–100, default 60). A successful response includes verdict, confidence, and a _algovault metadata block containing regime, signal_count, and weight_breakdown. The full response schema is in the quick-start docs.
Step 3 — Wire into your agent loop
Below is the terminal output from the TypeScript reference implementation running in DRYRUN_MODE. HTTP 406 indicates the API key does not have access to the requested asset at the requested confidence tier:
# AlgoVault MCP example — assets=BTC confidence_threshold=70
[BTC] ERROR: HTTP 406
# DRYRUN_MODE=1 — example complete
DRYRUN_MODE=1 disables live execution and is the correct flag for validating loop logic without consuming API quota. The 406 response means the asset or confidence tier is outside your current plan — upgrade the key or lower confidence_threshold to 60. The full reference example.ts pattern is in the AlgoVault docs: call get_trade_signal, check isError, branch on verdict, skip on HOLD, act on LONG or SHORT with your own position-sizing and risk logic.
Pitfalls and Design Decisions
Three honest gotchas before you ship this to production.
Rate limits are account-level, not per-asset. The default tier allows 60 requests per minute shared across all assets on the account. If your agent polls 20 assets simultaneously on a 60-second interval, you will hit the ceiling inside the first loop cycle. The correct pattern is a staggered queue: each asset polled on its own timer offset, not all fired at once. The 429 response includes a Retry-After header — respect it or implement exponential backoff with jitter. Full tier details and burst behaviour are documented in the rate limit reference.
Long-tail asset coverage degrades gracefully, not silently. The composite verdict runs across 724+ assets, but assets below a daily volume threshold of approximately $2M on the primary venue return lower-confidence verdicts and route to HOLD more frequently. This is the regime classifier expressing uncertainty when underlying data is thin — a correct behaviour, not a bug. If you are building on low-liquidity assets, begin with confidence_threshold=50 and calibrate upward once you have enough call history on your specific asset set to assess accuracy.
The regime classifier has a confirmation lag at transitions. When the market shifts from trending_bull to volatile, the classifier waits for 2–4 confirmed candles before updating the weight allocation. During that window, the composite may carry stale momentum weighting. This is a deliberate trade-off: waiting for confirmation prevents false regime switches, which the published call history showed were causing more edge-case losses than a 2-candle lag. The data drove the architecture. Agents should avoid increasing position size on the first candle of any new trend signal — wait for the regime field in _algovault metadata to confirm the transition first.
What the Data Shows
The headline is 89.9% PFE win rate across 72,565+ verified calls, but the number that matters for calibrating your agent is win rate segmented by asset class and regime type.
Majors outperform in trending regimes. BTC and ETH directional calls show the strongest per-regime consistency in trending_bull and trending_bear classifications. Liquidity stability is the underlying driver: the weighting model has the deepest call history on major assets, and the regime classifier's confirmation signal is faster and cleaner when order-book depth is high. Mid-cap assets (roughly ranked 50–200 by market cap) show lower consistency in volatile regimes but hold strong results in trending conditions — consistent with what you would expect from a data-flywheel effect compounding over time.
HOLD frequency reflects the live selectivity rate published at algovault.com/track-record. Across all assets and regimes, the selectivity mechanism operates as designed. Agents that override HOLD calls and trade those periods should not expect the published win rate to apply — the HOLD filter is load-bearing, not advisory. Building logic that respects HOLD is the single most reliable way to inherit the published performance profile.
Merkle verification is third-party auditable. The track record is not self-reported. AlgoVault publishes Merkle batches on Base L2, each committing a batch hash of verified call outcomes to chain. Third-party auditors can verify any individual call using the published Merkle proof — the numbers are independently reproducible, not asserted. The verification toolkit and on-chain batch references are documented at algovault.com/track-record.
CTA
The composite verdict is live across 724+ assets today.
Start with the track record — the Merkle-verified call history is the fastest way to calibrate your confidence threshold for your target asset class: algovault.com/track-record.
Then read the docs — the quick-start guide covers install, first call, and the full _algovault response schema with field-level documentation: algovault.com/docs.
Source and reference implementations are on GitHub: github.com/AlgoVaultLabs.
Mr.1 — AlgoVault Labs
